
Wörter zählen von LaTeX-Dokumenten
Hierfür gibt es zwei Möglichkeiten:
- Zählung der Wörter im Quellcode.
- Zählung der Wörter im fertig kompilierten Dokument, z.B. im PDF.
Beide Methoden haben ihre Tücken: Wer die Wörter im Quellcode zählen will, muß beachten, daß keine Kommandostrukturen (z.B. Präambel, Formatangaben, Makros) oder auskommentierten Absätze mitgezählt werden. Fertig kompilierte Dokumente enthalten dagegen ggf. sich wiederholende Kopfzeilen mit der Kapitelüberschrift oder Seitenzahlen, die ja für eine plausible Wortanzahl eigentlich auch nicht mitgezählt werden sollten. Manchmal werden auch am Zeilenende umgebrochene Wörter als zwei Wörter gezählt oder gar nicht, wenn sie eine komplexe Ligatur-Glyphe enthalten. All das verfälscht die korrekte Anzahl der Wörter.
Am sinnvollsten ist es, den reinen Quelltext zu zählen. Man muß nur ein Programm benutzen, das die Kommandostrukturen und Kommentare nicht mit in die Zählung einbezieht.
Wörter im Quelltext zählen
Das geht über verschiedene Wege, ich stelle hier einige vor.
- Benutzung von
texcount. Dieses kleine Perl-Script ist in den großen TeX-Distributionen enthalten, bei TeXLive unter GNU/Linux im Pakettexlive-extra-utils. Die Anwendung erfolgt, indem über die Konsole folgender Befehl eingegeben wird:texcount [Optionen] [Datei], also z.B.texcount -sum Datei.tex⟶ als Ausgabe erfolgt die Anzahl in Summe, pro Kapitel, pro Header und nur für den Haupttext. Wer weitere Angaben braucht, sollte die Dokumentation nach den zahlreichen möglichen Optionen durchsuchen. Sehr nützlich ist noch die Option-inc, die alle eventuell überinclude-Makros eingebundenen Teildokumente mit durchzählt. - Über den KDE-Editor »Kile«: Hier wird über den Menüpunkt Datei | Statistik eine Statistik des aktuell geöffneten Dokuments angezeigt (Wort- und Zeichenanzahl usw.). Gemäß der Kile-Programmierung werden hierfür wohl alle Kommando-Elemente ausgeblendet bzw. nicht mitgezählt, so daß man die reine Anzahl der Wörter des Quelltextes erhält.
- Kommerzielle Editoren wie der Sublime-Text-Editor können mit Plugins für LaTeX-Unterstützung ausgestattet werden. Eines davon, »LaTeXing« bringt eine Funktion mit, die Wörter ebenfalls direkt aus dem Quelltext heraus zu zählen; ein anderes Plugin namens »LaTeX Word Count« tut das ebenfalls (und zählt unsinnigerweise alle ausgeblendeten Kommentare mit!). Ähnliche Plug-Ins gibt es bei anderen großen Editoren: Emacs, Visual Code usw.
Wörter im PDF zählen
Manchmal ist es erforderlich, in einem PDF die Wörter zu zählen, z.B., wenn man nicht über den Quellcode verfügt.
- Wer unter Windows den Adobe PDF-Reader benutzt, kann sich eine Java-Erweiterung namens »Abracadabra-Tools« installieren, die neben anderem Schnickschnack u.a. ein Wörterzähl-Algorithmus enthält.
- Linuxer sind meistens schneller dabei und machen das über die Kommandozeile:
pdftotext Dokument.pdf - | wc -w(hierbei wird das PDF zunächst in ein Textdokument konvertiert und dann über die Pipe an den »word count« (wc)-Algorithmus übergeben. Als Ausgabe nur die Wortanzahl (Option-w).
Die zurückgegebene Wortanzahl liegt aber meist nicht sehr nah an der Wirklichkeit, weil Seitenzahlen, umgebrochene Wörter und andere Dinge mitgezählt werden.
Im Vergleich
Je nach Methode weicht die am Ende ausgerechnete Wortanzahl erheblich voneinander ab (siehe Grafik). Für diesen Vergleich wurden außerdem zwei weitere Methoden aufgenommen:
- Die Zählung der Wörter der reinen .tex-Datei mit der oben angegebenen Methode:
wc -w Dokument.texSelbstverständlich wird hierbei nicht inhaltssensitiv unterschieden, d.h. alle Wörter der Präambel und isoliert stehende Kommandos im Quelltext werden mitgezählt. - Die Zählung des Textes, nachdem er in eine Textverarbeitung, hier LibreOffice Writer, hineinkopiert wurde. Wie jede vernünftige Textverarbeitung zeigt der LO Writer nämlich auf Wunsch die
Anzahl der getippten Wörter an. Vor Zählung der Wörter wurden selbstverständlich die Präambel entfernt, sowie alle LaTeX-Kommandos in Formatierung übersetzt, also z.B.
\textit{Wort}zu Wort. Damit blieb reiner Text übrig, so wie ich ihn auch im Writer tippen würde. Allerdings habe ich hier auch alle auskommentierten Notizen behalten.
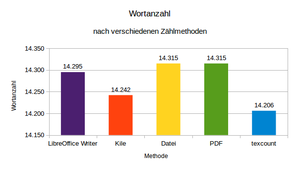
Links eine Auswertung zur Wortzählung nach verschiedenen Methoden. Als Text habe ich eine meiner Novellen verwendet. Die Methode »LibreOffice Writer« ist die Zählmethode des Textes nach LO Writer-interner Zählstatistik (keine Präambel oder Befehle, aber Kommentare). Die 2. Zählmethode »Kile« ist mit dem Kile-internen Wortzählalgorithmus des ursprünglichen Quelltextes gezählt worden (keine Kommandos, ohne Kommentare?). Bei Methode 3 (»Datei«) wurde der Inhalt der vollständigen .tex-Datei über die Kommandozeile gezählt (also auch Wörter der Kommandostruktur, Präambel usw.). Bei Methode 4 (»PDF«) wurde das fertige PDF wieder in eine Textdatei zerlegt und diese, wie eine Methode vorher beschrieben, gezählt. Obwohl das PDF weder Präambel noch Kommentare noch LaTeX-Kommandos enthält, ist die Wortanzahl identisch mit dem reinen Quelltext. Methode 5 (»texcount«) zeigt das wahrscheinlich verläßlichste Ergebnis an. Der Unterschied zwischen Methode »LO Writer« und »Kile« ist eigenartig. Da im Writer nur reiner Text ohne Kommandos steht, hätte ich hier eine kleinere Wortanzahl als bei der Quelltext-Zählung durch Kile erwartet. Der Unterschied ist möglicherweise Resultat dessen, daß im Kile auch die auskommentierten Bereiche nicht mitgezählt werden, beim LO Writer aber schon.
Letztendlich empfehle ich die Quellcode-Zählung mit texcount.