
Freie Desktop-Datenbanken
– mit drei Beispielen und allgemeinen Hinweisen –
Einführung
Desktop-Datenbanken unterscheiden sich von Serverdatenbanken in einigen wichtigen Vorzügen: Es handelt sich um weniger komplexe Datenaggregate, die man leichter weitergeben kann. Eine Base-Datenbank hat die Dateiendung .odb und kann, wie z.B. eine Access-Datenbank (.accdb), als einzelne Datei (E-Mail, USB-Datenträger) weitergegeben werden. Gleiches gilt für SQLite-Datenbanken (siehe unten). Desktop-Datenbanken eignen sich daher auch für kleinere Datensammlungen (Probenliste, Telefonbuch, Literaturverwaltung), die man als Einzelnutzer bearbeitet und füttert.
Einige für den Linux-Desktop populäre Frontends für Desktop-Datenbanken werden unten exemplarisch vorgestellt und verglichen.
Datenbanken statt Tabellendokumenten
Wer die Arbeit mit Tabellendokumenten (Excel, LibreOffice Calc u.a.) gewohnt ist, wird sich diese Frage vielleicht nie gestellt haben: Warum sollte ich nicht stattdessen eine Datenbank benutzen? Welche sind die Unterschiede, welche die Vorteile? – Durchaus, es gibt sie!
Ein Tabellendokument mag auf den ersten Blick sehr einfach zu benutzen sein: Mit einem leeren Dokument (Excel oder Calc) sieht man für gewöhnlich ein Tabellenraster, das man sogleich mit Daten füllen kann.
- Ob man Spaltennamen später hinzufügt: Egal.
- Ob man Zahlen und Text in dieselbe Spalte eingibt: Egal.
- Ob man ganze Zahlen oder Währungsbeträge in dieselbe Spalte eingibt: Egal.
- Ob der eine Wert gerundet wird, der andere nicht: Egal.
- Ob man nur zwei Buchstaben oder einen ganzen Textabsatz hinterlegt: Egal.
- Schriftarten? Jede Zelle kann eine eigene haben.
- Diese Zelle kursiv, die andere fett? Die eine blau hinterlegt, die andere grün? Alles ist möglich.
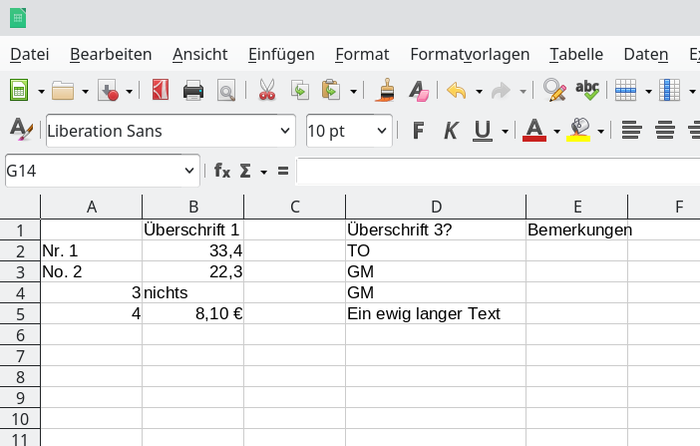
Wir sehen: Eine Tabellenkalkulation nimmt jede Form von Daten auf; um die Ordnung muß sich der Anwender kümmern, sofern es ihn überhaupt interessiert.
Das ist insgesamt nicht gut. Daten gehören üblicherweise dahin, wo sie hingehören. Nämlich in eine Datenbank. Tabellenkalkulationen haben ihre Daseinsberechtigung, sie können ja auch nachträglich mit der Datenbank (Quelle) verbunden und zur Auswertung/Visualisierung der Daten genutzt werden. Aber Rohdaten gehören immer in die feste Struktur einer Datenbank.
Gegenüber einem Tabellendokument bietet eine Datenbank weitere Vorzüge, von denen ich hier die wichtigsten nenne:
(A) Datenintegrität: Jedes Feld (Variable, Spalte) entspricht einem festen Datentyp und nimmt nur diesen auf:
- Wird ein Feld als Dezimalzahl deklariert, dann verweigert es die Eingabe von Buchstaben.
- Soll ein Textfeld nur 10 Zeichen aufnehmen, wird die Eingabe von 12 Zeichen verweigert.
- Soll ein Feld nur Zahlen zwischen -5 und +5 enthalten, wird die Eingabe von +7 verweigert.
- Oder man gibt vor, daß nur die folgenden X Einträge ("Rot", "Blau", "Schwarz"; "Schweiz", "Belgien", "Italien") erlaubt sind.
- Felder können die Anweisung erhalten, daß sie nie leer bleiben dürfen, oder daß sie einen bestimmten Wert nie enthalten dürfen, andernfalls wird eine Warnung ausgegeben oder das Speichern des Datensatzes verweigert.
Diese Form der Eingabe garantiert eine sichere und zuverläßige Ablage von Informationen. (In einem Tabellendokument kann man mittels Formeln ebenfalls gewisse Strukturen vorgeben, etwa, daß nur Einträge eines bestimmten Wertebereichs oder aus einer Liste erlaubt sind.)
(B) Datensatz: Ein Datensatz entspricht genau einer "Zeile" in einer Tabelle. Alle Variablen (= Felder = Spalten) dieser Zeile gehören immer zusammen, und werden über eine eindeutige ID referenziert. Die einzelnen Einträge können durch Sortieren oder Filtern nicht durcheinandergewürfelt werden; sie gehören zu einem festen Set, dem "Datensatz". Dateneinträge können also durch Vorgänge des Abfragens, Filterns oder Sortierens niemals durcheinandergeraten, wie dies in Tabellendokumenten bei unsachgemäßer Handhabe vorkommen kann. Es gibt nicht wenige Beispiele (in Wirtschaft, Medizin oder Wissenschaft), wo falsche Ergebnisse auf "kaputtsortierte" Datenstände (nur 1 Spalte sortiert statt alle Spalten) oder einen falschen Zellenbezug in Formeln zurückzuführen sind!
(C) Formulare: Die Nutzung von Formularen vereinfacht weiterhin die Dateneingabe und schafft Überblick. Durch das Sperren ungenutzter Felder vermeidet man falsche und unnötige Eingaben (auch in einem Tabellendokument lassen sich Zellen, Bereiche oder Tabellenblätter durch Sperrung vor Veränderung schützen.)
(D) Kapazität: Die modernen Tabellendokument-Formate (Excel, LibreOffice Calc) können ca. 1 Million Zeilen bei mehreren 10.000 Spalten fassen. Das Ganze läßt sich dann auf mehreren Tabellenblättern multiplizieren. All das klingt nach sehr viel, doch denkt man an heutige Datensammler von Meßstationen, kann über mehrere Monate ein Vielfaches davon zusammenkommen. Es ist nicht unwahrscheinlich, daß man mit einem Tabellendokument schlichtweg an die Fassungsgrenze kommt. Datenbanken kennen diese Einschränkungen üblicherweise nicht; hier gibt es zwar auch Grenzen für die Einzeltabellen und Gesamtgröße der Datenbank, doch die liegt im Bereich von Terabytes oder mehr.
(E) Verknüpfung von Datentabellen: Die Verknüpfung von Tabellen mittels einer ID gehört zum Tagesgeschäft der relationalen Datenbanken. Die Auftrennung von Daten auf mehrere Tabellen wirkt dem Sammeln von Redundanzen entgegen und spart damit Speicherplatz. Gleichzeitig wird die Fehlerwahrscheinlichkeit reduziert.
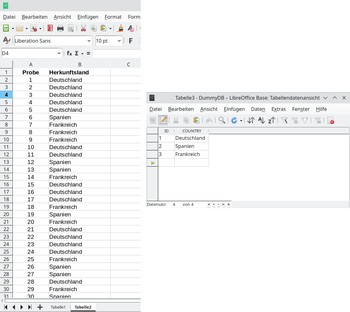
Ein Beispiel: In einer internationalen Probensammlung gibt es ein Feld "Herkunftsland". Stammen nun 2000 Proben aus Deutschland, 500 aus Spanien, 200 aus Frankreich, müßte man in der Tabelle die entsprechende Anzahl der Einträge "Deutschland" usw. wiederholen. Es wird also 2000mal das Wort "Deutschland" gespeichert, und ohne Mustererkennung könnten sich auch Fehleinträge wie "Deutchland" oder "DeutschIand" (großes Binnen-I) unbemerkt darunter befinden (Abb. 2, links). In einer Datenbank würde man die sich wiederholenden Einträge nun in eine separate "Länder-Datenbank" auslagern: Diese separate Tabelle enthält nur die Einträge "Deutschland", "Spanien" und "Frankreich" (also 3 Worte), jeweils mit einer eigenen ID 1 bis 3 (Abb. 2, rechts). Diese ID würde anstelle des Wortes hinterlegt. Es gibt nur diesen einen Eintrag, nur diese eine Schreibweise. Eine Änderung oder Löschung des Eintrags wirkt sich auf alle verbundenen Datensätze aus.
(F) Trennung von Daten und Berechnungen/Abfragen: Dies ist vermutlich der größte Unterschied zwischen Datenbanken und Tabellendokumenten: In einer Datenbank werden die reinen Rohdaten strukturiert gesammelt, und alle darauf basierenden Berechnungen oder Datenzusammenstellungen (über Filterung oder Gruppierung) geschehen mittels eigenen Abfragen (üblicherweise SQL-basiert), die sich selbstredend in der Datenbank für den wiederholten Aufruf speichern lassen. In einem Tabellendokument kann es durch Verschiebungen, das Einfügen von Spalten und Zeilen oder andere Operationen dazu kommen, daß Zellenbezüge von Formeln nicht mehr stimmen; daß außerdem der Überblick verloren geht, welche Datenfelder einen Rohwert angeben, und welche das Ergebnis einer Berechnung sind. Die Wahrscheinlichkeit für Fehler wird mit einem Tabellendokument maximiert!
(G) - Mehrbenutzerzugriff: Es trifft nicht unbedingt auf Desktop-Datenbanken zu, doch erlauben Datenbanken üblicherweise die gleichzeitige Nutzung und Bearbeitung durch mehrere Benutzer. Ein Tabellendokument (Excel, Calc) wird dagegen für andere Bearbeiter gesperrt (nur zum Lesen), sobald es geöffnet wird.
Für weitere Hinweise zur Benutzung einer Datenbank siehe ganz unten.
Beispiel: LibreOffice Base
HSQLDB
Base ist das Datenbankmodul der Office-Suite LibreOffice. Es kann Kontakt herstellen zu ganz unterschiedlichen Datenbanktypen, arbeitet aber standardmäßig mit einer eingebetteten HSQLDB-Datenbank = Desktop-Datenbank.
Die Abhängigkeit von Java führt traditionell zu einem großen Speicherhunger, und tatsächlich waren frühere Base-Versionen gekennzeichnet von einer gewissen Trägheit, selbst bei geringen Datenmengen. Das hat sich aber mittlerweile soweit gebessert, daß man auch mit sehr umfangreichen Datentabellen zügig arbeiten kann.
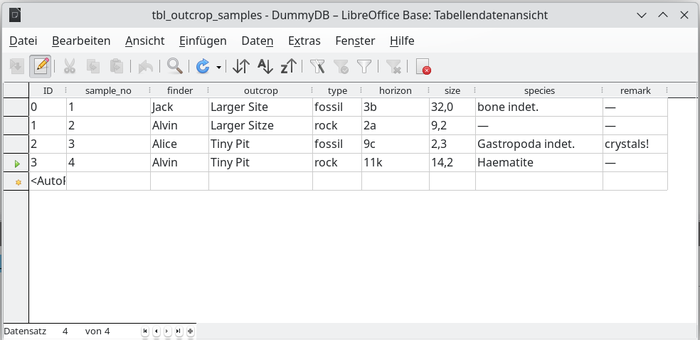
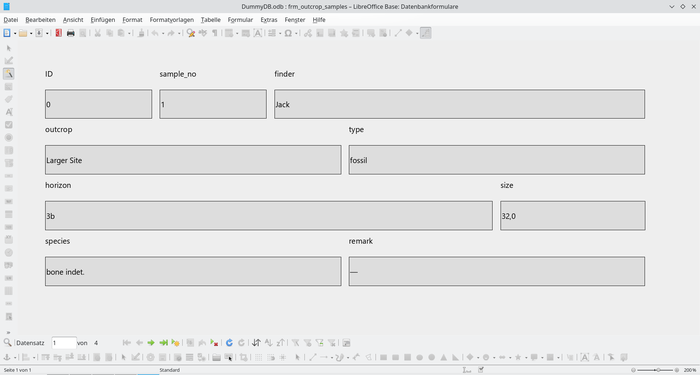
Base ist im Prinzip wie ein Klon von MS Access zu sehen: man erkennt die Module zum Entwerfen von Tabellen sowie die Module für Abfragen, Formulare (Abb. 4) und Berichte wieder. Es mag sein, daß noch nicht so mancher Komfort-Wunsch umgesetzt wurde; leider wurde die Base-Entwicklung in den vergangenen LibreOffice-Veröffentlichungen immer etwas stiefmütterlich behandelt. Dafür ist Base (anders als MS Access) vollständig in das LibreOffice-Ökosystem integriert, d.h. man kann über die sog. Datenquellen direkt aus anderen Anwendungen (Writer, Calc) auf Base-Datenbanken zugreifen. So kann man z.B. sehr einfach die Daten einer Base-Datenbank mit Calc in einem Diagramm wiedergeben.
Die Auswahl der Datentypen läßt keine Wünsche übrig, allein für numerische Felder stehen 9 verschiedene Typen zur Verfügung (Abb. 5).
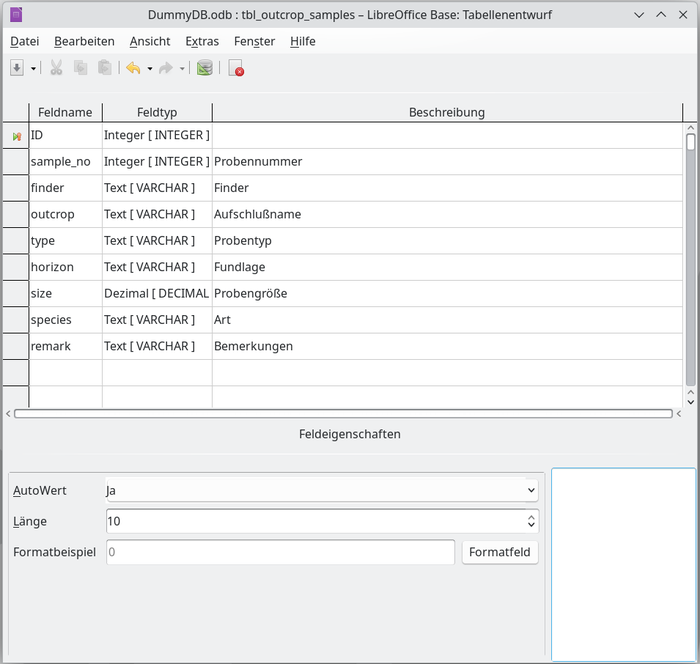
Die HSQLDB-Datenbank kann sowohl Kennwort-geschützt als auch im Lesemodus geöffnet werden. Schön ist die Möglichkeit zur Formatierung von negativen Währungsbeträgen in roter Schriftfarbe.
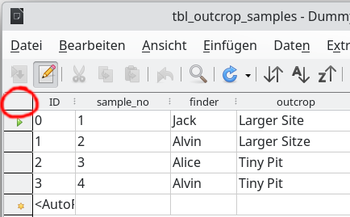
Abschließend noch ein selten dokumentierter Kniff (und in Foren oft gefragt): Die Schriftgröße einer Base-Tabelle läßt sich tatsächlich anpassen: Rechtsklick oben links in das 1. Feld beim Schnittpunkt von Spalten und Zeilen (Abb. 6, roter Kreis).
Firebird
Neben "embedded HSQLDB" läßt sich auch eine lokale Firebird-Datenbank einrichten. Gegenüber HSQLDB besteht keine Abhängigkeit zu Java (daher sehr viel schneller bei Lese- und Schreibzugriffen!), allerdings ist ein JDBC-Treiber notwendig. Firebird ist mit C/C++ programmiert und erfuhr gegenüber HSQLDB zahlreiche Bugfixes.
Ansonsten ist die Bedienung mit HSQLDB identisch, da dasselbe Frontend (Base) benutzt wird. Lediglich die Auswahl der Datentypen ist etwas abweichend.
Man beachte, daß eine LEERE Firebird-Datenbank (Datei-Endung .fdb) bereits 1,5 MB belegt. Bei HSQLDB im .odb-Container sind es nur 2,35 kb; bei SQLite (siehe unten) sind es 8 kb; bei Kexi (siehe unten) sind es 32 kb.
Die Entscheidung "HSQLDB oder Firebird" würde man letzlich vermutlich nur anhand der Lese- und Schreibgeschwindigkeit großer Datenmengen treffen. Bei kleineren Datenmengen ist kein Unterschied feststellbar.
Beispiel: DB Browser for SQLite
Die Software "DB Browser for SQLite" ist ein Frontend für sqlite-Datenbanken (Endung .sqlite). Es gibt zahlreiche Vor- und Nachteile bei der Benutzung einer sqlite-Datenbank mit diesem Frontend.
Konzeptbedingte Merkmale bei sqlite-Datenbanken
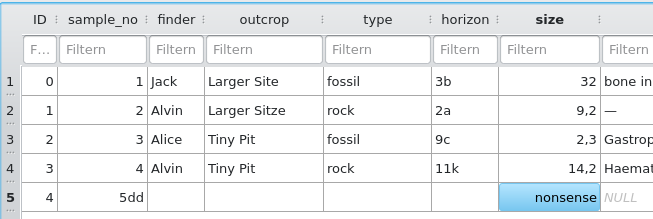
Der wichtigste Punkt ist: sqlite-Datenbanken arbeiten nicht typenkonform, d.h. man kann in numerische Felder wie INTEGER auch Text eintippen (Abb. 7), oder bei numerischen Feldern mit Dezimaltrenner sowohl Komma als auch Punkt verwenden (Punkt wäre richtig!). Diese Freizügigkeit ist eine große Gefahr für die Datenintegrität und die Fehleranfälligkeit von Eingaben! Werden numerische Werte mit Komma-Dezimaltrenner importiert, sehen sie zunächst OK aus (Abb. 7, Spalte "size"), werden aber als Text verstanden. Erst, wenn man alle Kommas in Punkte umwandelt (Suchen & Ersetzen) werden daraus "numerische Werte", mit denen man in Abfragen rechnen kann!
Glücklicherweise kann man im SQLiteBrowser beim Anlegen einer Datenbank eine Option "strict" anwählen, womit die eingegebenen Daten zum Typenfeld passen müssen ("erweitert" aufklappen!).
Zweitens bietet sqlite viel weniger Datentypen als die anderen Datenbanken. Beispielsweise gibt es keinen Typ DATE -> man kann stattdessen in einem Textfeld die ISO-Schreibweise "1999-04-12" nutzen. Auch gibt es keinen Typ BOOLEAN (Ja/Nein, 0/1) -> auch hier wird ein Textfeld mit J/N, Y/N, Ja/Nein oder ein Zahlenfeld mit 0/1 gefüllt. Unter den numerischen Feldern gibt es lediglich INTEGER (Ganzzahlen), REAL (alles mit Dezimalstelle, aber ungenauer Floating Point) und NUMERIC (für exakte Vorgabe von Dezimalstellen).
In vielen Fällen kommt man mit Text- und Zahl-Feldern gut hin. Aber man muß bei der Eingabe höllisch aufpassen.
Sqlite hat aber auch zwei große Vorteile:
- Die Datenbank ist ausgesprochen flink. Man kann nur staunen, wie schnell riesige Datenmengen geladen und gefiltert werden.
- Die Datenbank funktioniert »standalone«, da keinerlei Abhängigkeiten bestehen. Alles, was sqlite zum Betrieb benötigt, bringt die Datenbank-Datei selbst mit. Ideal für die Weitergabe.
DB Browser for SQLite als Frontend
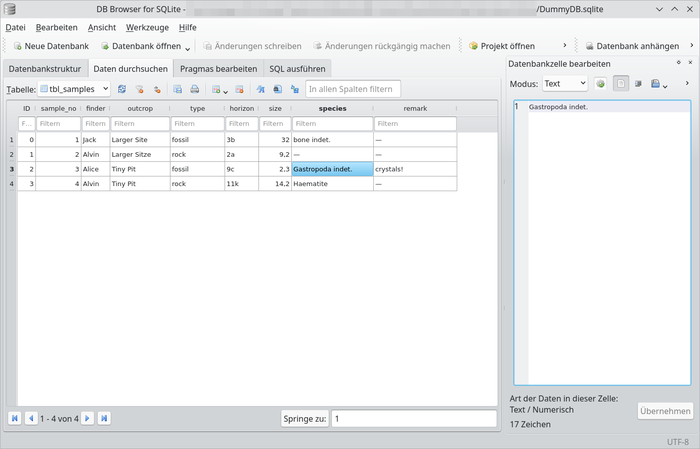
Die GUI ist einfach und übersichtlich gehalten. Auf separate Module für Formulare oder Berichte muß man verzichten. Dafür gibt es ein großes Text-Eingabefeld (Abb. 8, rechts). Über jeder Spalte steht ein Filterfeld (Abb. 8), das bei Eingabe von Werten eine Live-Filterung vornimmt – das ist angenehm und bequem. Die Filtereinstellung kann dann auch gleich als Abfrage übernommen und gespeichert werden.
Verschiedene Module lassen sich im Fensterrahmen verankern, z.B. für die Datenbankstruktur. Ein bemerkenswertes Fenster-Modul nennt sich "Diagramm" und erlaubt die Visualisierung von zwei numerischen Datenreihen in einem XY-Plot, ganz ohne zusätzliche Software (Abb. 9)!
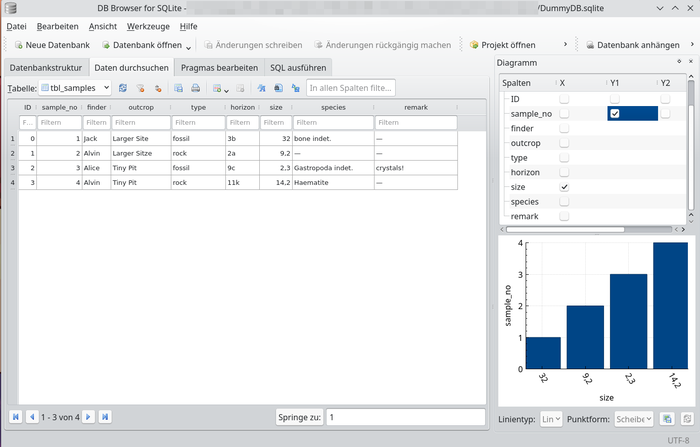
Bemerkenswert ist außerdem die Möglichkeit zur bedingten Formatierung (wie man sie aus Tabellendokumenten kennt): Mit Vorgabe einer Bedingung ("FELD >= 5") können die Datensätze unterschiedlich eingefärbt werden. Diese Formatierung wird allerdings nicht in der sqlite-Datenbank gespeichert, sondern in einer separaten Projekt-Datei des Programms DB Browser for SQLite.
Ein weiteres bemerkenswertes Feature betrifft die Dateneingabe: Denn anders als in anderen Datenbanken können Werte über Datensätze hinweg kopiert oder gelöscht werden. Wie in einem Tabellendokument kann man einen Bereich mit der Maus markieren und dann alle Zellen in diesem Bereich auf NULL oder einen Wert aus dem Zwischenspeicher setzen. Das geht freilich nur, weil keine Typenkonformität besteht (siehe oben). Die Arbeit mit Copy & Paste führt aber zu einer raschen Eingabe sich wiederholender Werte.
Eine sqlite-Datenbank kann im Lesemodus geöffnet oder mit einem Kennwort-Schutz versehen werden (Letzteres über SQLCipher). Ein Index- und ein VAKUUM-Befehl stehen zur Datenbank-Optimierung zur Verfügung.
SQL-Abfragen werden in sog. VIEWS gespeichert, doch sie lassen sich, einmal gespeichert, nicht modifizieren. Will man an einem bestehenden VIEW (Abfrage) etwas anpassen, muß der SQL-Code der Abfrage kopiert und in ein neues VIEW eingefügt werden. Das finde ich etwas umständlich.
Die Verkettung von Tabellen finde ich mit dem Programm etwas holprig gelöst. Es scheint zuweilen, daß Fremdschlüsselstandards ignoriert werden. Und obwohl man die Spaltenreihenfolge einer Tabelle ändern kann (Felder mit Pfeil-rauf/runter verschieben), wird dieser Vorgang oftmals nicht gespeichert oder mit einer Fehlermeldung quittiert. Möglicherweise sind das Bugs, die mittlerweile behoben worden sind.
Die sqlite-Datenbank kommuniziert aus DB Browser for SQLite mit keiner anderen Anwendung (eben »standalone«). Für den Datenaustausch ist also der Export über das CSV-Format notwendig, das mit einem Rechtsklick auf die entsprechende Tabelle aber leicht gelingt. Ebenso einfach lassen sich bestehende CSV-Dateien importieren.
Beispiel: Kexi
Kexi wird mit der Calligra-Office-Suite ausgeliefert. Das Programm legt im Format .kexi eine Desktop-Datenbank an. Die Oberfläche ist ausgesprochen rudimentär und besteht aus nur wenigen (!) Buttons und Einstellungsmöglichkeiten. Import und Export von Daten funktionieren tadellos und sehr einfach. Im Tabellenentwurf muß man sich mit nur wenigen Datentypen zufriedengeben, immerhin wird die Datenkonformität beachtet (kein Text in Zahlenfelder). Module für das Erstellen von Abfragen, Formularen und Berichten sind vorhanden, allerdings ohne Assisstenten, d.h. man muß die gewünschten Felder selbst plazieren. Über die Geschwindigkeit der Datentabellen bei großen Datenmengen kann ich nichts sagen.
Abschließende Hinweise zur Benutzung einer Datenbank
Zur fachgerechten Benutzung einer Datenbank sollten folgende Hinweise beachtet werden.
Atomare Datenablage
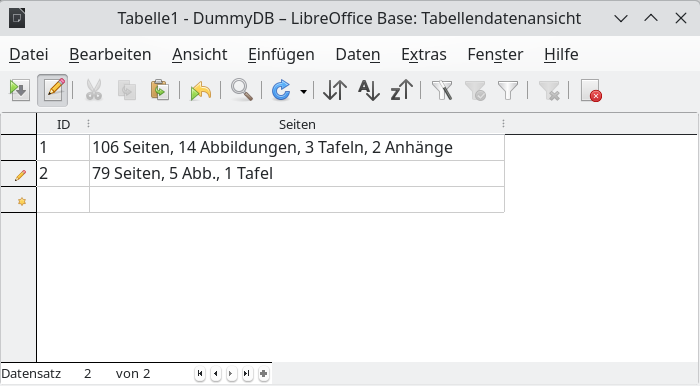
Informationen sind »atomar« zu trennen, d.h. es gibt Felder für jeden Typ an Information. Unsauber ist es, mehrere »trennbare« Informationen in einem gemeinsamen Feld unterzubringen (Abb. 10). (Unpassend ist außerdem, daß ein Feld »Seiten« Informationen enthält, die nicht »Seiten« sind.)
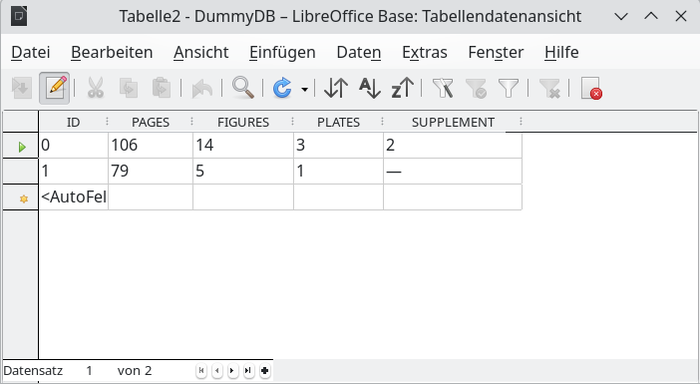
Richtig ist die Aufteilung auf entsprechende Felder (Abb. 11):
Leerfelder vermeiden
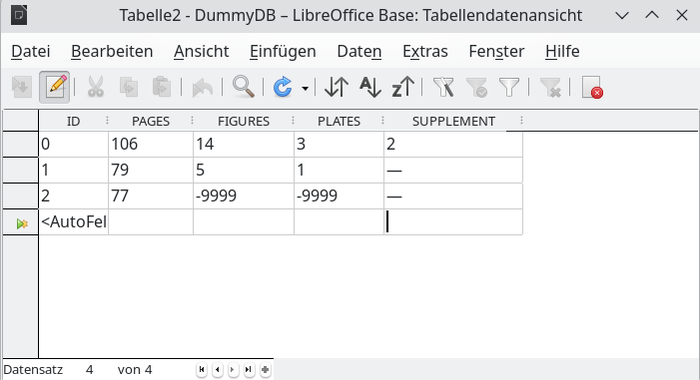
Leere Felder sollte es nicht geben; jedes Feld verdient einen Eintrag:
- in Textfelder könnte man den Wert NULL oder einen Geviertstrich — eingeben (Abb. 12)
- in Zahlenfeldern ist der Dummy-Wert -9999 zur Kennzeichnung eines fehlenden Wertes üblich (Abb. 12). (Sofern das Zahlenfeld auch negative Werte aufnehmen kann)
- Bei Boolean-Feldern (0 oder 1 als Eintrag) werden nicht nur die Ja-Datensätze (=1) gekennzeichnet, sondern alle anderen mit »0« (und nicht »NULL«).
Datenbankstruktur ausschließlich mit ASCII-Zeichen anlegen
Beim Anlegen von Tabellen- und Spaltennamen sind Zeichen außerhalb des ASCII-Datensatzes zu vermeiden. Also Tabellennamen nicht schreiben als Übersicht, sondern
Uebersicht.
- Am sichersten fährt man, wenn Objekt- und Spaltennamen gleich eine englische Bezeichnung zugewiesen bekommen:
SIZEstattGröße. - Eine Begrenzung der Länge des Spaltenbezeichners ist eigentlich nicht mehr aktuell. Bei alten Datenstrukturen wie dem ESRI-Shape-Format für Geodaten ist man noch auf 8 Zeichen pro Spalte beschränkt.
- Abkürzungspunkte sind Tabu! Also nicht
Nr., sondernNr(für Nummer) - Spaltennamen, wenn vermeidbar, nicht mit einer Ziffer beginnen lassen.
- Kurze, sinnvolle und treffende Namen wählen: Nicht
NummerDerSedimentologischenSchicht, sondernSchichtoderLayer. NichtGrößeDesGemessenenFossils, sondernSizeoderLengtho.ä. - Immer in Einzahl schreiben:
VornamestattVornamen,BemerkungstattBemerkungen
Formatierung von Spaltennamen
Spaltennamen können auf verschiedene Weise angegeben werden. Alles mit Vor- und Nachteilen:
- Pascal Case:
FossilSpeciesoderLayerThickness - Snake Case:
fossil_speciesoderlayer_thickness - Kebab Case:
fossil-speciesoderlayer-thickness(gefährlich, da Bindestrich bei Abfragen als Minus gelesen werden kann) - Camel Case:
fossilSpeciesoderlayerThickness
Es gibt auch Leute, die setzen Feldnamen (Spaltennamen) ausschließlich in Großbuchstaben, um sie leichter von anderen Variablen unterscheiden zu können: FOSSIL_SPECIES oder
LAYER_THICKNESS
Präfix nutzen
Objekt- und Feldnamen sollten nicht allein stehen, sondern im Namen einen Bezug zur übergeordneten Struktur enthalten:
- Tabellenbezeichnungen beginnen mit
tbl_, z.B.tbl_sample_list - Abfragenbezeichnungen beginnen mit
qry_(von Query), z.B.qry_best_of - Formularbezeichnungen beginnen mit
frm_, z.B.frm_Start - Berichtsbezeichnungen beginnen mit
rpt_(von Report), z.B.rpt_final
Auch Spaltennamen einer Tabelle sollte man entsprechend kennzeichnen, gerade wenn sie sich auf verschiedenen Tabellen wiederholen. Angenommen, das Feld LABEL gibt es in einer Tabelle
tbl_sample_list und tbl_laboratory, dann könnte man die Felder SL_LABEL und LAB_LABEL nennen. Auch das erleichtert später die Auswahl und
Eingabe in Abfragen. Das alles sollte man sich vorab gründlich überlegen (Datenbankkonzeption), weil ein späteres Umbenennen nur Probleme verursacht.
Wohin mit den Einheiten?
Numerische Inhalte (besonders Skalargrößen wie Temperatur, Masse usw.) haben üblicherweise eine Einheit, die irgendwo angegeben werden sollte, um den Inhalt einer Spalte richtig zu verstehen und zu verrechnen. Auch hierfür gibt es verschiedene Möglichkeiten:

Option 1: Die Einheit wird in der Spaltenbeschriftung integriert.
Die Einheit selbst wird dann mit einem Unterstrich oder einem _in_ abgetrennt. Verständnisprobleme sind spätestens dann zu erwarten, wenn die Einheit komplizierter wird, z.B.
Tm3a (Tausend m³ pro Jahr). Außerdem dehnt sich die Spaltenlänge unnötig auf. Das ist v.a. dann unangenehm, wenn der eigentliche Wert 1-stellig, aber die Spaltenbezeichnung
20-stellig ist.

Option 2: Die Einheit wird in einer separaten Spalte untergebracht.
Hier wird sozusagen die Spaltenbezeichnung wiederverwendet und ein »_Einheit« o.ä angefügt. Dadurch entsteht Verwechselungsgefahr. Außerdem verbreitert sich die Tabelle um die Anzahl der jeweiligen Einheiten-Tabellen, im schlimmsten Fall ist sie also doppelt so breit.

Mit dieser Methode (Option 2) können die Einheiten entweder wiederholt geschrieben werden, oder sie werden in eine separate Tabelle ausgelagert und dann per ID verknüpft. Letzterer Weg ist allgemein in Datenbanken empfehlenswert, da
- Schreibfehler vermieden werden,
- bei 20.000 Datensätzen nicht 20.000 mal derselbe Werte gespeichert wird.
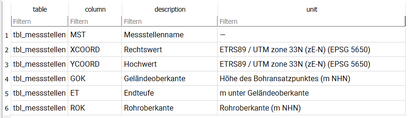
Option 3: Die Spaltenerläuterungen und -einheiten werden in eine separate Tabelle ausgelagert.
Diese Tabelle liegt separat (unverknüpft) in der Datenbank vor und ist rein informativ: Hier kann man sich austoben mit Erläuterungen, Einheiten und Kommentaren. Empfehlenswert ist ein Feld für die jeweilige Tabelle. So kann man das Erläuterungsblatt für mehrere Tabelle und deren Spalten verwenden. Dieses Verfahren hat den Vorteil, daß es unabhängig von der Datenbankart oder -programm eingesetzt werden kann.
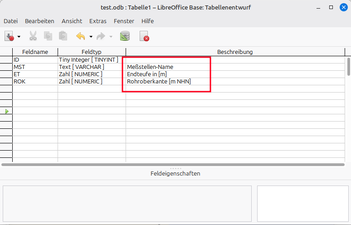
Option 4: Manche Datenbanken mit GUI (LibreOffice Base, MS Access u.a.) erlauben im Entwurfsmodus der Tabelle das Unterbringen von Kommentaren.
In einigen Datenbankprogrammen wird bei einer geöffneten Tabelle der Inhalt der Kommentarspalte dann in der Statusleiste angezeigt. Das hängt allerdings von der Art der Datenbank und des Datenbankprogramms ab.