
Gebrochene Schriften mit TeX setzen
Einiges zum Setzen gebrochener Schriften (vorrangig die Fraktur als Lese-Schrift) habe ich bereits hier geschrieben, darunter die Erwähnung des TeX-Pakets yfonts, mit dem man Frakturtexte geringer typographischer Qualität setzen kann.
Das Grundproblem bleibt folgendes: Der Einsatz gebrochener Schriften erfordert mehr typographisches Geschick, als man es gewohnt ist: zwei wichtige Elemente davon sind Ligaturen und der Gebrauch des langen Minuskel-s. Programmierte Schriften, wie sie von Ligafaktur angeboten werden, übernehmen diese Notwendigkeiten automatisch, sofern man sie in einer herkömmlichen Textverarbeitung wie LibreOffice Writer gebraucht.
Bei der Arbeit im TeX-Quellcode müssen stattdessen alle "besonderen" Glyphen, nämlich das spezielle lange s und die vielen Ligaturen, mit einem Umweg angesprochen werden, da sie keinem Buchstaben auf einer Tastatur entsprechen. Stattdessen steuert man die entsprechende Glyphe (Zeichen) direkt über den Glyphen-Code der Zeichentabelle an. Voraussetzung ist, daß man XeTeX oder LuaTeX benutzt.
Die Glyphe in der Zeichentabelle identifizieren
Hierfür gibt es verschiedene Möglichkeiten. Zeichentabellen gibt es viele und sie sind je nach Betriebssystem unterschiedlich. Unter Linux kann man "Font Manager" verwenden, der in den meisten Paketquellen verfügbar sein sollte.

Links das Fenster des "Font Manager". Mit Auswahl einer Schriftart sieht man unten die Glyphentabelle. Klickt man die gewünschte Glyphe an (hier das lange Minuskel-s, roter Pfeil), wird die Unicode-Kennung ausgegeben (roter Rahmen). Das lange Minuskel-s wird also mit "017F" codiert.
Die Glyphe im Quellcode eingeben

Im TeX-Quellcode müssen nun (von Hand!) alle betreffenden Stellen "ausgetauscht" werden. (Suchen & Ersetzen nicht empfehlenswert!) Die gewünschte Glyphe wird nun mit
\char"XXXX eingegeben, wobei XXXX mit dem oben identifizierten Code ersetzt wird. Für das lange Minuskel-s schreibt man also \char"017F
Dieser "Code-Block" wird auch mitten im Wort eingefügt (Abb. 2, rot unterstrichen).
In Abbildung 2 sind zwei identische Beispielsätze eingegeben worden. In der unteren Zeile wurde außerdem die ch-Glyphe (siehe hier, dort Abschnitt 5.1) des ersten Wortes "Ich" ersetzt. Deren Kennung folgt ein Escape-Zeichen (Abb. 2, grüner Pfeil), um das Leerzeichen zum nächsten Wort zu gewährleisten.
Der Quellcode kann abschließend mit XeTeX oder LuaTeX kompiliert werden (bei der Beispiel-Konfiguration in Abb. 2 mit XeTeX).
Stolperstellen
Korrekter Schriftname
Im Beispiel Abb. 2 wird die Schrift "Alte Schwabacher" benutzt. Das ist aber nicht die Schriftkennung, womit die Schrift auf dem Betriebssystem identifiziert wird:
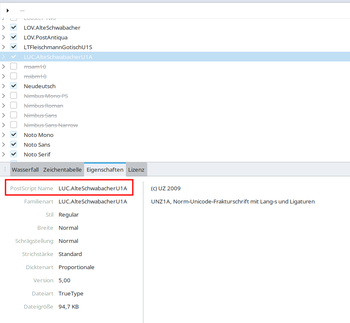
Noch einmal das Anwendungsfenster von "Font Manager", womit sich der PostScrip-Name der Schrift herausfinden läßt (roter Rahmen): Dieser wird im Quellcode benutzt
(LUC.AlteSchwabacherU1A).
Ligafaktur-Schriften
Sollen Schriften der Ligafaktur-Webseite verwendet werden, sind die Schriften vom Typ "LUC" anzusteuern. Die Typen "LOV" sind dagegen die vollprogrammierten Schriften für die Benutzung in einer Textverarbeitung wie LibreOffice Writer mit automatischer Ligaturen- und lang-s-Ersetzung.
Unicode-Kennung mit vorangehender Null
Beginnt eine Unicode-Kennung mit einem Buchstaben, ist eine "0" voranzustellen: In Abbildung 2 wird die ch-Glyphe im Wort "Ich" verwendet. Diese Glyphe hat die Kennung F1BB, sie
beginnt folglich nicht mit einer Ziffer. Beim Kompilieren von \char"F1BB würde ein Fehler ausgegeben. Stattdessen wird eine Null vorangestellt (Abb. 2, roter Pfeil).
Nachteile
- Der Quellcode wird durch die zahlreichen Ersetzungen grob unübersichtlich. Eine Rechtschreibprüfung wird unzweckmäßig. Viel Fehlerpotenzial für Buchstabendreher und fehlende Satzzeichen.
- Insbesondere die zahlreichen Ligaturen einer Frakturschrift werden vom Schriftendesigner aufgrund fehlender Standards auf die "Free-Use"-Plätze verlegt. Ändert der Designer diese Plätze (neue Version der Schriftart), sind die Eingaben im TeX-Quellcode obsolet.
Direkte Eingabe der Unicode-Glyphe im Quelltext
Eine alternative Vorgehensweise besteht in der direkten Eingabe der jeweiligen Glyphe im Quelltext. Das funktioniert aber nur mit Unicode-kompatiblen Compilern wie XeTeX und LuaTeX.

Die betreffende Glyphe wird aus der Zeichentabelle in die Zwischenablage kopiert – und dann hier im Quellcode wieder eingefügt. Zeile 13 in Abb. 4 zeigt die Eingabe: das lange Minuskel-s wird (zweimal) direkt dargestellt, während die ch-Ligatur im ersten Wort nicht korrekt dargestellt wird. Kompilieren läßt sich das ganze trotzdem. Die Zeilen 11 und 13 führen zum selben Ergebnis. (Zeile 9 ist wortgleich, aber es fehlt die ch-Ligatur.)
Der Quellcode wird auf diese Weise wieder einigermaßen lesbar, aber es bleibt eine aufwendige Nachbearbeitung. Die automatische Rechtschreibprüfung des Editors wird vermutlich trotzdem nicht korrekt arbeiten.
Folgender (sinnfreier) Beispiel-Text wurde mit zahlreichen Ligaturen, Umlaut-Varianten und der Fraktur eigenen Glyphen gefüllt:

Der Quellcode. Einige der Spezial-Glyphen werden einigermaßen lesbar dargestellt, andere nur als "Tofu"-Blöcke.

Das mit XeTeX kompilierte Ergebnis ist einwandfrei.

Zum Vergleich noch einmal die oben beschriebene Eingabemethode mit dem \char-Makro und der Zeichenkennung. Der Quellcode wird dadurch leider auch nicht leichter lesbar. Das
kompilierte Ergebnis entspricht jedoch Abb. 6.